For example, we could also get this type of data while importing intermediate tables, and we would like to delete redundant rows before actually adding them into the production tables. Moreover, we should not leave the prospect for duplicating rows because duplicate information allows multiple handling of requests, incorrect reporting results and more. However, if we already have duplicate rows in the column, we need to follow specific methods to clean up the duplicate data. Let’s look at some ways in this article to remove data duplication.
How to Remove Duplicate Rows from a SQL Server Table?
There are a number of ways in SQL Server to handle duplicate records in a table based on particular circumstances such as:
Removing duplicates rows from a unique index SQL Server table
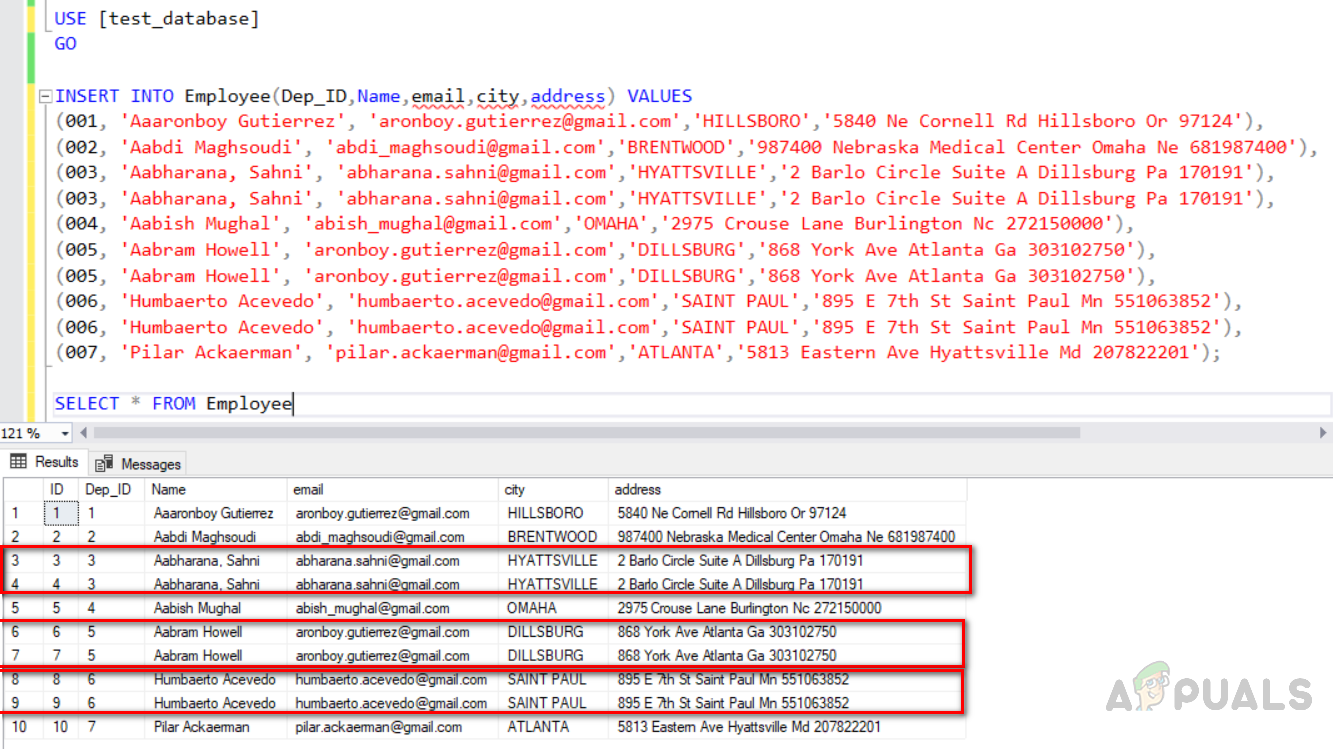
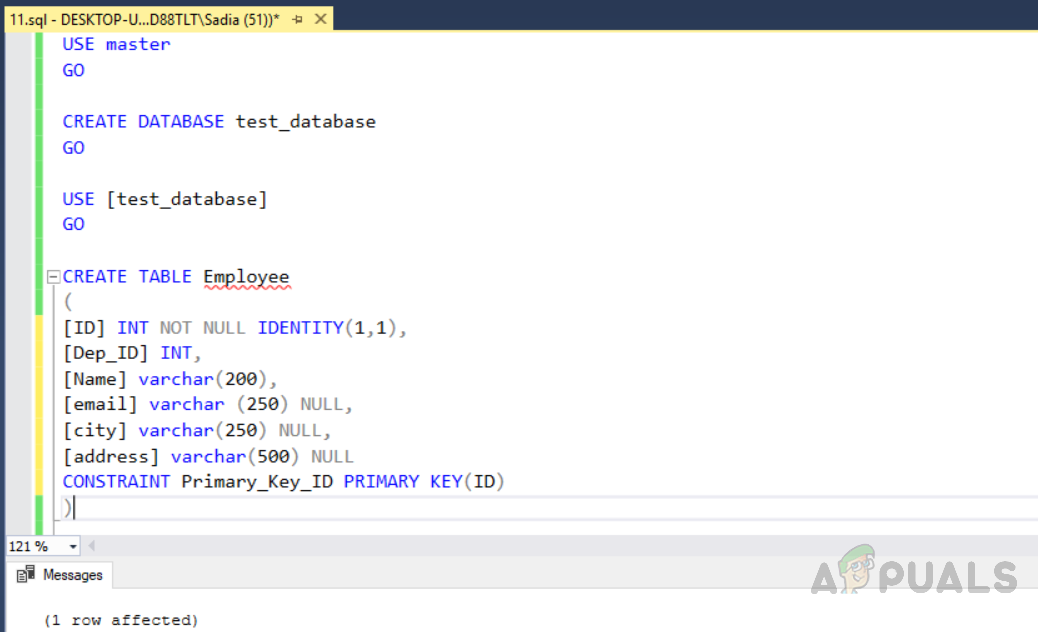
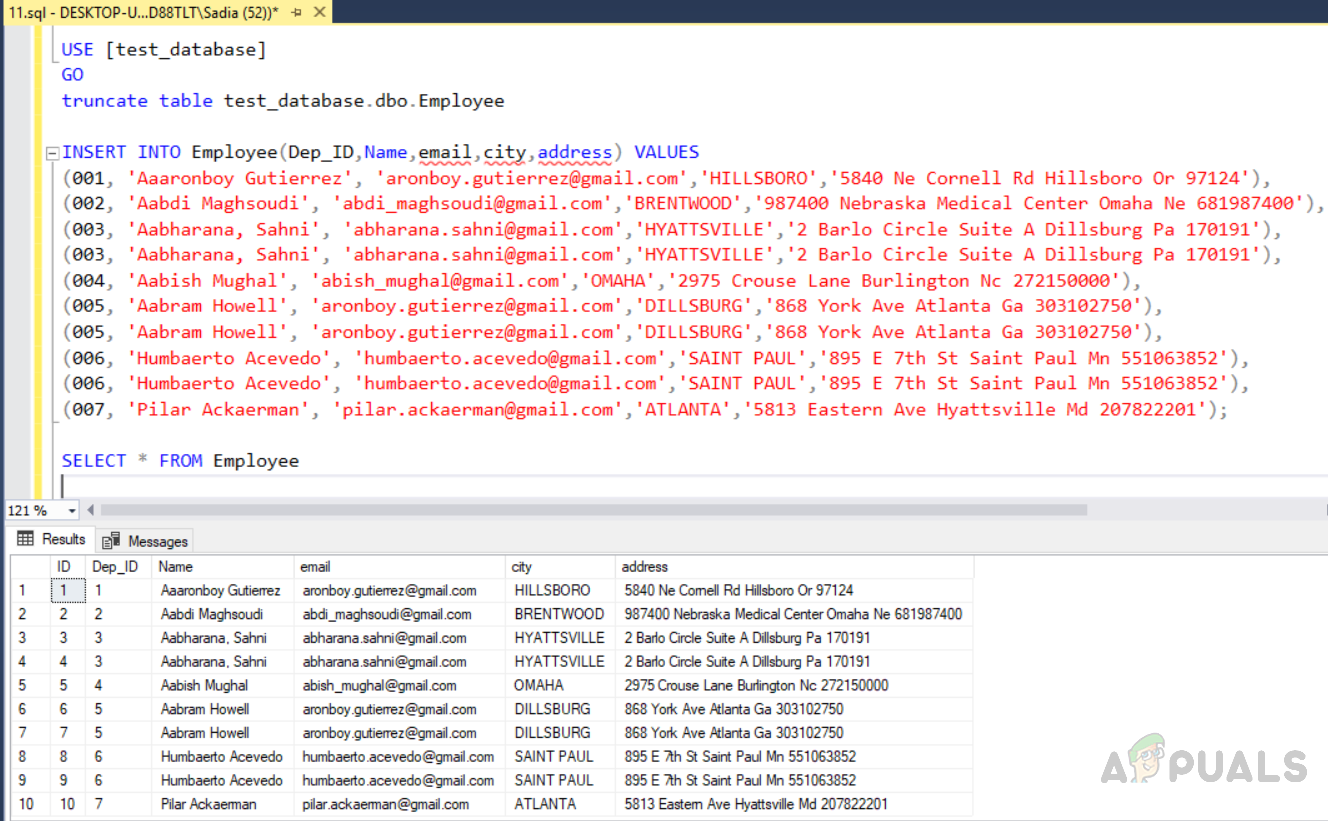
You can use the index to classify the duplicate data in unique index tables then delete the duplicate records. First, we need to create a database named “test_database”, then create a table “ Employee” with a unique index by using the code given below. The output will be as below. Now insert data into the table. We will insert duplicate rows also. The “Dep_ID” 003,005 and 006 are duplicate rows with similar data in all fields except the identity column with a unique key index. Execute the code given below. The output will be as follows. Now find the no of rows in the table by executing the following code. The count(*) function will count no of rows. The output will be as below. Row no (3, 4), (6, 7), (8, 9) highlighted in the red box are duplicate ones. Our task is to enforce uniqueness by removing duplicates for the duplicate columns. It is a little easier to remove duplicate values from the table with a unique index than to remove the rows from a table without it. Given below are two methods to achieve this. The first method gives you duplicate rows from the table using the “row_number()” function, whereas the second method uses the “NOT IN” function. Thes two methods have their own cost which will be discussed later.
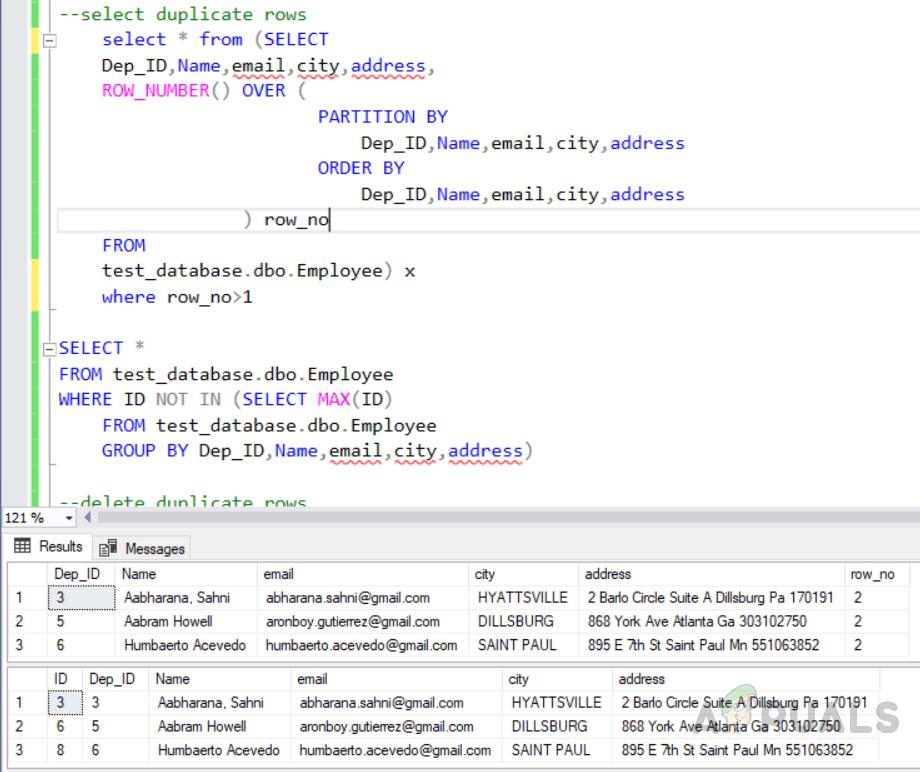
Method 1: Selecting duplicate records using “ROW_NUMBER ()” function
Method 2: Selecting duplicate records using “NOT IN ()” function
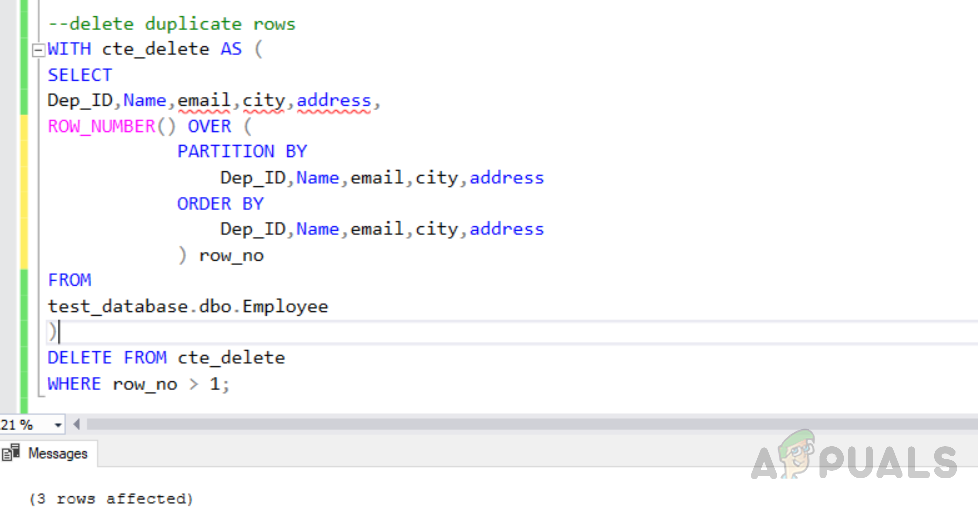
Execute the above code and you will see the following output. Both methods give the same result, but they have different costs. Now we will delete the above selected duplicate rows using “CTE” by using the following code. The following code is selecting duplicate rows to be deleted using the “ROW_NUMBER ()” function.
Method 1: Deleting duplicate records using “ROW_NUMBER ()” function
The output will be as below.
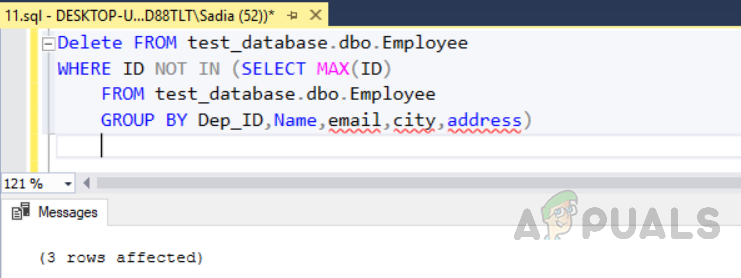
Method 2: Deleting duplicate records using “NOT IN ()” function
Now in order to test another method, we need to truncate the table which will remove all the rows from the table. Then insert command will add values to the table. Execute the following code now. The output will be as given below. Execute the code given below to delete all the duplicate rows from the table “Employee”. The output will be as follows.
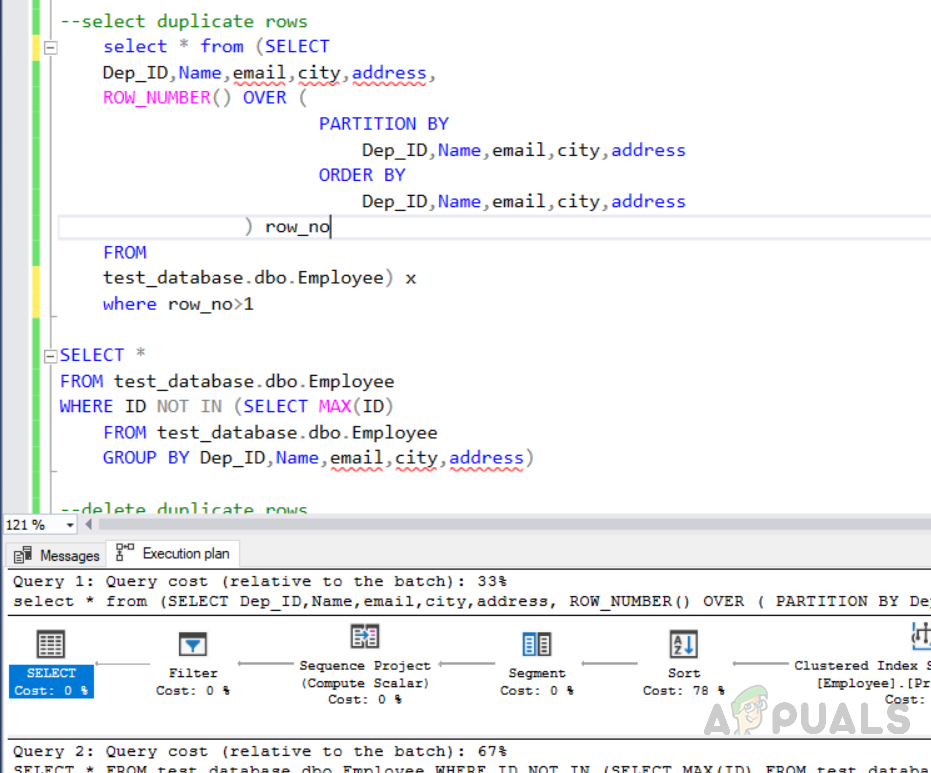
Execution Plan and Query Cost for deleting duplicate rows from the indexed table:
Now we have to check which method will be cost-effective and taking fewer resources. Select the code and click on the execution plan. The following screen will appear showing all executing plans along with cost percentage. We can see that method 1 “deleting duplicate records using “ROW_NUMBER ()” function” have 33% cost and method 2 “deleting duplicate records using NOT IN () function” has 67% cost. So the method one is most cost-effective as compared to method two.
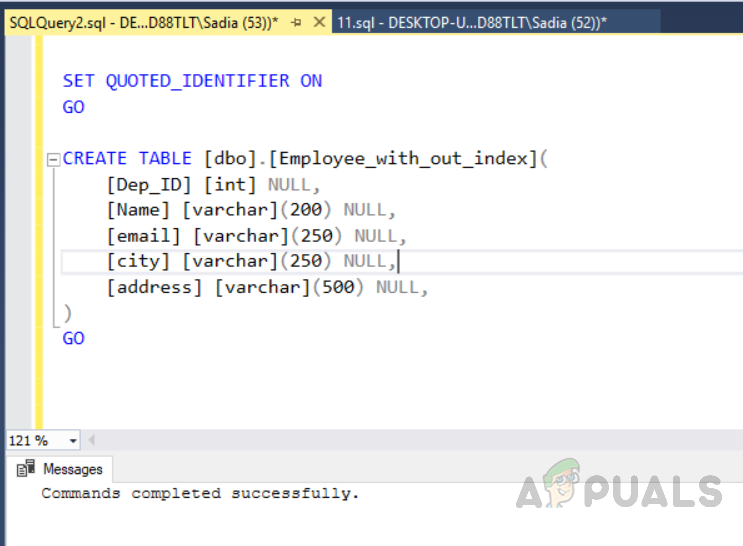
Removing duplicates from a SQL Server table without a unique index:
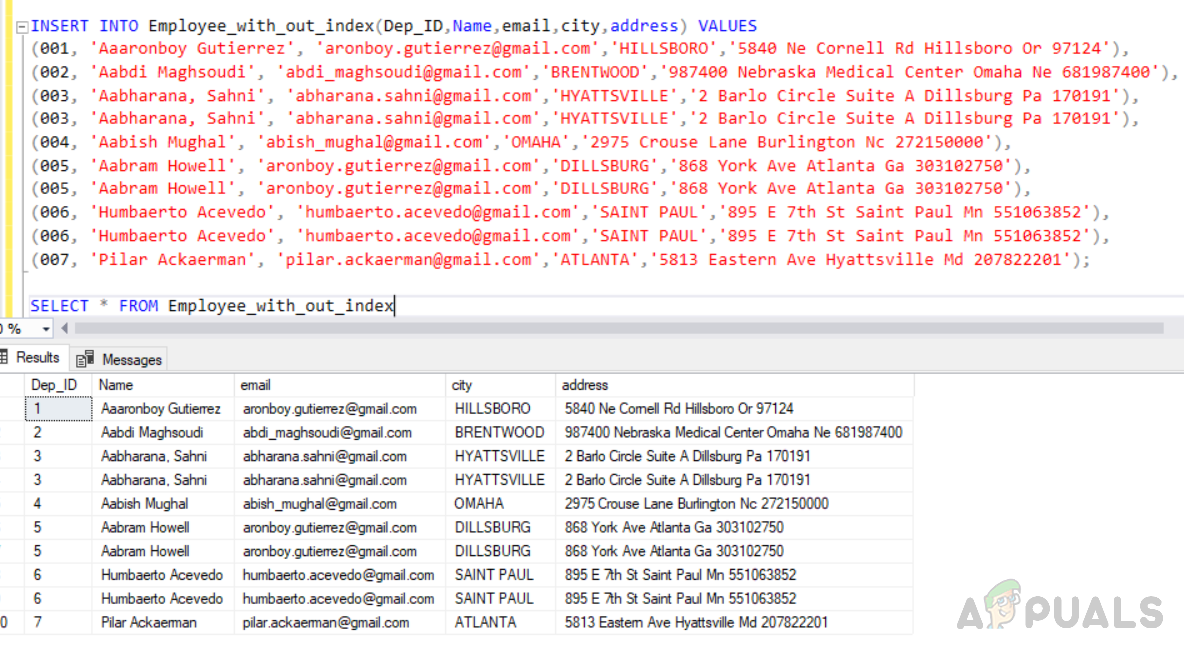
It’s a bit more difficult to remove duplicate rows or tables without a unique index. In this scenario, using a common table expression (CTE) and the ROW NUMBER() function helps us in removing the duplicate records. To remove duplicates from the table without a unique index we need to generate unique row identifiers. Execute the following code in order to create the table without a unique index. The output will be as follows. Now insert records into the created table named “Employee_with_out_index” by executing the following code. The output will be as follows.
Method 1: Deleting duplicate rows from a table using the “ROW_NUMBER ()” function and JOINS.
Execute the following code which is using ROW_NUMBER () function and JOIN to remove duplicate rows from the table without index. IT first creates a unique identity to assigns row_no to all the rows and keep only one-row removing duplicate ones. The output will be as follows.
Method 2: Deleting duplicate rows from a table using the “ROW_NUMBER ()” function and PARTITION BY.
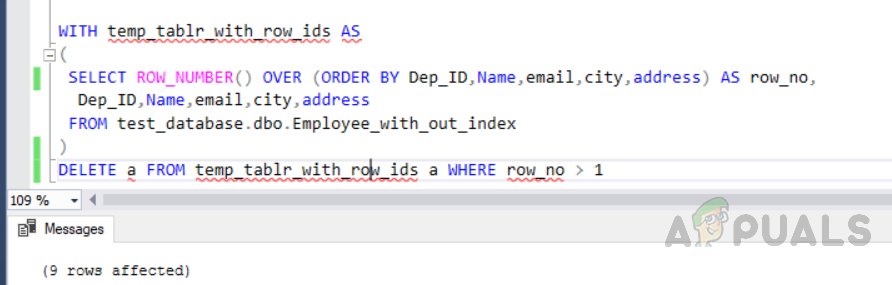
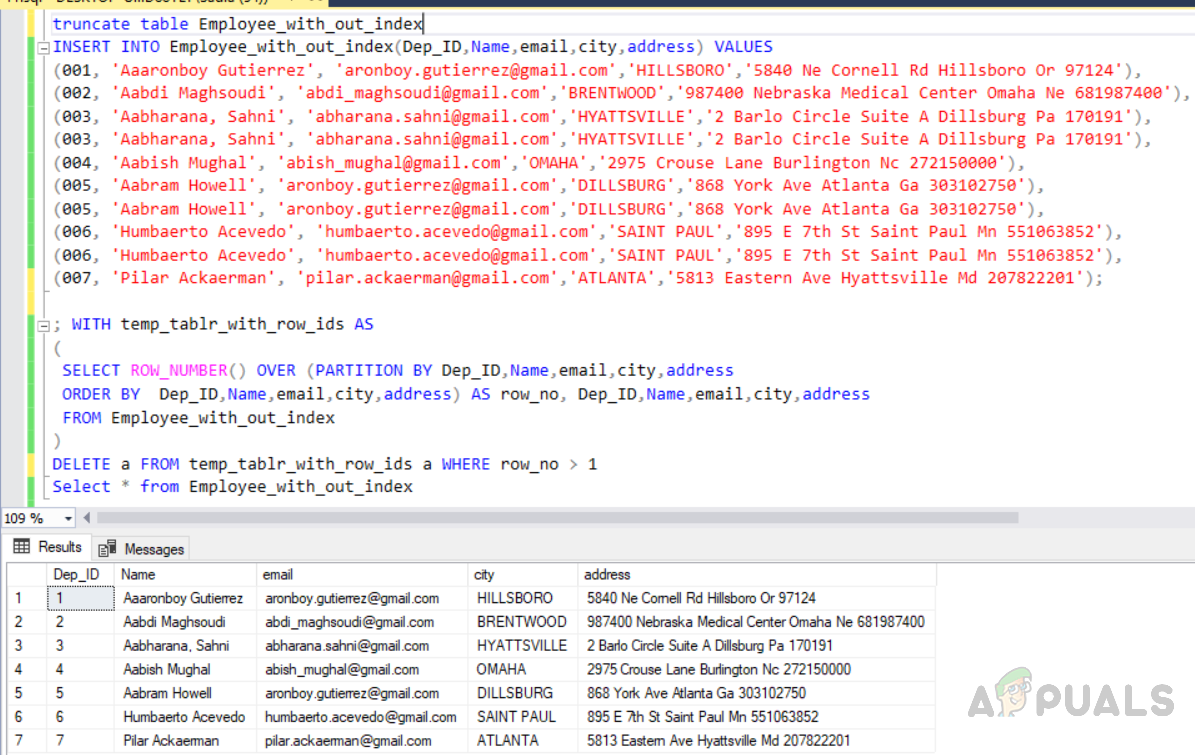
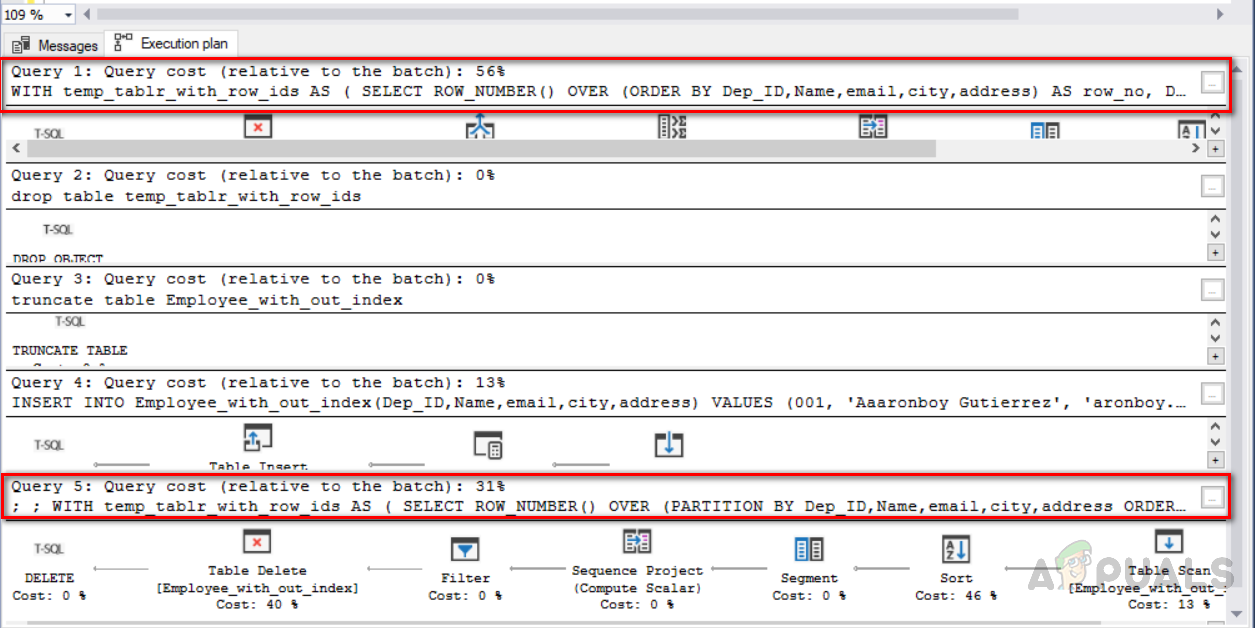
Now, in this method, we are using ROW_NUMBER function along with partition by clause in order to assign row_no to all the rows and then delete duplicates ones. First of all, we need to truncate the same table we have created earlier so that all the data gets deleted from the table. Then, insert records into the table including the duplicates records. The third query will delete duplicate rows from the table named “Employee_with_out_index”. Selecting duplicate records into the temp table Deleting duplicate records from the temp table The output will be as follows. Furthermore, we need to know about query execution costs in order to understand which one is an optimized solution. So you need to select all the relevant queries and click on the execution plan. The image below shows the execution plan for the queries along with execution cost. Delete queries are highlighted in the red box. The first query which is using “ROW_NUMBER ()” and JOIN clause has 56% execution cost, whereas the second query is using “ROW_NUMBER ()” and “PARTITION BY” has 31% cost. So the second method is a more optimized one and we should follow an optimized solution.
How to Shade Rows and Columns in Microsoft ExcelHow to Delete Multiple Rows in Excel?How to Insert and Delete Entire Rows and Columns on Microsoft ExcelHow to Fix the Error ‘A Network-related or Instance-specific Error occurred…